如果能力值可以由自己决定,那不是很好吗?
2022/12/12
written by Ran
此文汉译了FLEXSCHE创始人 初代CEO 浦野 幹夫(Urano Mikio)于2021/7/5发布在
FLEXSCHE日文网站博客的内容。
我们FLEXSCHE公司20年来一直不断开发APS高级计划排产系统。您一定会觉得都已经做了20年了,肯定没有剩下什么未知领域可以探索了吧・・・可是其实还有很多很多。
其中一个就是如何清除使我们在引进APS系统时畏手畏脚犹豫不前的一个巨大的障碍。
这个"巨大的阻碍"正是"数据整备"。虽说恰当正确建模和排程规则当然是很重要的,但仅有那些是不够的。为了能够拟定高精细的计划,还需要尽可能正确估算各个工序的所需工作时间,尽力给出恰当的"能力值"。
为了加工抛光某产品的某零部件,做1个需要10分钟还是需要30分钟呢・・・生产排程是建立在一系列这样的预估(预测)累积之上的。作为数据给出处理单位数量所需的时间,即"能力值"。 如果工作时间因抛光机器不同或从事工作的人员而异,要求的精度越高,所需的数据就越详细、越庞大。
从前我们不得不将这些能力值作为数据逐个维护进来。这就是刚才提到的"巨大的障碍"。如果主系统中已经有了信息那么我们可以将其导入进来。但例如为了计算成本作为参考数据虽然绰绰有余,可如果要排产其精度却不足以作为计划排程的根据。也许这些数据和生产计划排程的粒度完全不同。
当然以这种粗能力运转也是一个办法,也能取得一些效果。但是、
"希望不会出现违交期"
"希望将浪费的库存降至最低"
"希望尽可能的减少加班"
"希望增大工厂的产出"
"希望杜绝现场计划混乱问题"
等等、为了雄心勃勃地追求只有APS高级排程系统才能解决的挑战,进一步提高计划精度是一个值得挑战的重大课题吧。
许多人都知道,克服这一障碍将带来巨大的回报,但另一方面,这个障碍巨大到让人感到胆怯也是可以理解的。
在这里请大家随我想象一下。 如果一开始只给出粗略的能力值,随着系统的运行,准确性会逐渐提高・・・如果有这样一个系统,您会不会感觉很不错呢?
这就是FLEXSCHE公司成立第20年,(实在不好意思)才迟迟着手的挑战。
将其以"FLEXSCHE DataTuner(福勒克歇・数据调谐器)"的形式商品化。
从FLEXSCHE版本20开始以选项产品的形式推出 。
积累样本数据
能力根据所使用的资源(机械、设备、工人、工具,有时是电力、工作场所等,在进行某项工作时使用)而有所不同。 它还根据要处理的对象(称为品目)而有所不同。 为了能够正确进行计划排程,必须为每个品目设置各个资源的能力值。
为了知道一个资源的能力,也许可以通过实际执行工作和计测来了解。 具有恒定处理速度的自动设备可能只要进行一次计测(或通过阅读设备的说明书)就可以了解,但可惜的是,大多数情况都不是那么简单的。 因为每次工作时通常都会有 "波动",所以通常不可能只通过一次测量就得到正确的能力值。
请想象一下如果要计测"用吸尘器清扫一个20平米的房间所需的时间"。不需要解释的吧?可能两分钟就完事儿,有时候也可能需要七分钟吧。因人而异,也因吸尘器的类型不同而异吧。还比如扫除时孩子或宠物进来打扰,或者如果垃圾比平时多得多就会花更多时间吧。甚至可能计测出了差错算错了时间也说不定。
导致波动的原因有很多很多。
能力的差异取决于各个资源的类型,或各别差异
即使做同样的工作,使用不同种类的资源,自然能力也会有所不同。 此外也会根据各别状况(例如,本身质量问题或老化)而变化。
这种变动通常在人员(工人)资源更常见。有时候单纯是"老手是新手的1.5倍"这种情况,或"小张虽然擅长这个工作、但不擅长那个工作。小王则完全相反。"等情况也有,很多时候都很难确定妥当的能力值吧。
处理时间的"波动"
所有的物理现象都会有波动。在相同条件下处理一个工作 ,一次可能需要4分58秒,下一次可能需要5分8秒,都是很自然的。但是如果"每次都准确的需要5分1秒"这样的情况反而是很罕见的吧。特别是以人员为中心进行工作的时候工作时间必定伴随着很大的波动。
"波动"不仅在生产排程中是不确定性的主要来源,而且在对未来预测和计划生产的时候也是如此。 由于一种被称为 "蝴蝶效应 "的影响,在某个时间点发生的轻微波动会随着时间的推移产生更大的影响,但这可以通过在各过程之间提供适当的缓冲来在一定程度上避免。 然而很明显,"波动 "使 "测定恰当的能力值"变得十分困难。
异常值混入
对于如何处理因意想不到的问题而延误(虽然也有可能异常早)的工作是一个很难的问题。 收集结果时如果能够明确指出"这次的信息不正常"就好了,但实际上往往很难做出客观的判断。
因此,收集数据并进行自动判断是最理想的,但如果事先不知道"本来的能力"的时候,那么什么样的值应该被视为"异常值(异常值)"呢。 异常值检测有多种理论,但我尝试过的理论(至少出于生产调度排程目的)都不是很令人满意。 因此,我们将使用一种独特的判断方法,它是对现有理论的定制版本。
另外确实还有另外一种说法是,应该考虑到以一定概率可能发生的问题来估计能力,但在这里我们先不谈这个问题。
单纯的输入错误
使用键盘输入实绩的时候理应输入実績"10"的地方有时候可能一不小心错误的输入成"100"了吧。类似这样数值差异非常明显的时候是可以归类为异常值自动去除的,但例如将"212"误输入成"221"这样的情况恐怕就没有办法区别了。
解决这样的问题的唯一方法也许是使用不易受人为错误影响的系统吧。 例如,可以通过使用条形码读取数值或在工作开始和结束时通过按下按钮自动输入日期和时间等系统来避免人为错误。
波动如此之多,似乎无法直接计测应该作为计划依据的"时间"。 因此我们对多次计测的结果进行统计处理,"推定"出一个可以说是合适的单一能力值,并以此为基础制定未来的计划。
为了推定能力,需要一定数量的样本数据。 虽说如此但是我们无法通过事先多次计测后再进行推定,因此我们使用实际工作结果进行估算。 整体的流程就是首先作为初始值在一定程度上粗略估计能力值,之后边循环运作边收集样本数据,在积累的同时逐步进行推定。
分析工序内的详细内容
应该推定的并不仅仅是资源的能力值。
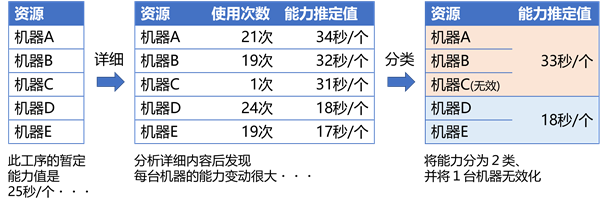
虽然对某工序的多个可用资源暂时设置了单一的能力值,但是有时候实际上是有一些变化的。如图所示、虽然对某工序可用的5台机器设置了制作1个产品需要25秒这样的粗略的暂定能力值,但基于实绩推定后发现可以将其分为两类,一类是慢的机器制造1个需要30秒以上、另外一类是快的机器只要20秒以下。
另外推定出机器 C 实际上基本没有使用。 如果排产系统每次都指定这些资源、但在车间现场每次都被订正,那么会影响计划的可行性(feasibility)和可靠性,也许将这些机器排除在计划之外比较好。
这里重要的是让我们可以人为介入进行判断干预,而不是自动做出这些判断。 在上面的例子中,如果机器C只是刚好最近闲置了,那么根据至多几十条数据,就将其排除在计划之外是不可取的。 如果基于长期积累的大量数据进行推定那么完全自动化也许是可以接受的,但产品种类繁多、产品生命周期短的制造业可能无暇等待吧。
参数化能力
让我们更进一步聊聊吧。
例如加工复杂程度不同但相似的6种零件的工序(工序1~工序6)、加工这些零件需要技能不同的6个工人(工人1~工人6)。
一种直接的建模方法是定义 6 个单独的流程,并将 6 个工分别设置能力值并作为可用资源。 在这种情况下,总共会有 36 个单独的能力值。
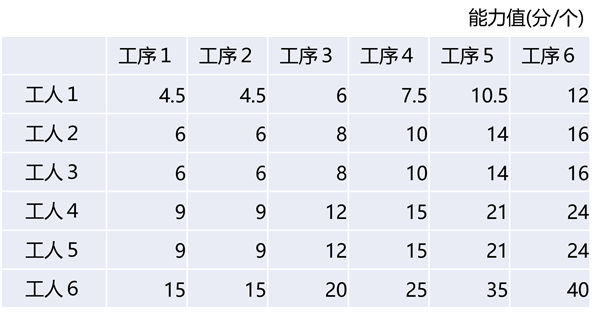
如果事先知道正确的值那么是没有问题的,但如果需要基于实绩进行推定,那么这不是一个好办法。
这么说是因为如果累积的数据存在偏差,那么可能会剩下无法推定的组合。 例如,假设我们已经积累了足够的总数据,但是没有工人1和工序1的组合的样本数据。 那么无论工人1的其他工序的工作结果和其他工人在工序1的工作结果再丰富,但只有工人1和工序1的组合是无法调优的,非常可惜。
这是因为没有活用无论由谁来处理复杂的零件都需要额外的时间,而高技能的工人处理事情的速度比其他人快,等等这样的相关性。 如果获得了除工人1以外的工人对工序1的加工时间的足够数据,如果发现它比其他零件花费的时间长几倍,则可以推定出工人1对工序1的加工时间也应相应地更长吧。
所以接下来优化一下建模。
将"加工的复杂程度"作为各个工序(与资源无关)的能力值。并将"工人的技能等级"作为工人资源的技能值。之后将工序和工人组合得出的能力值除以技能值的结果作为工作时间(用FLEXSCHE可以简单实现)。
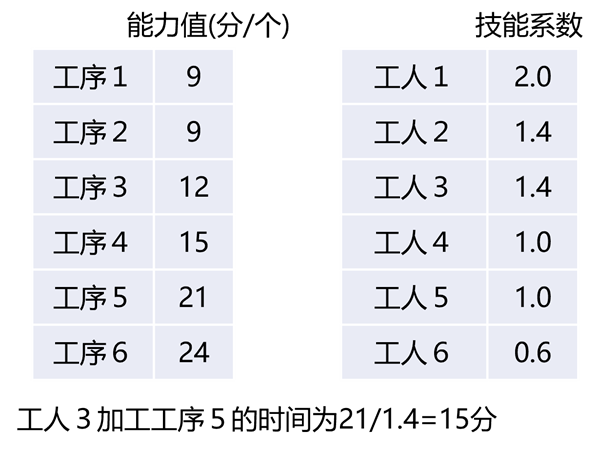
之后的逻辑部分稍微复杂所以在此省略不做详细介绍,就算对于某个组合没有直接的数据,只要能推定这12个数值,那么就可以推定出所有的组合的工作时间。由于需要调整的数值也从36个减少到12个,这使得它看起来易懂且便于维护。 在6和6的数值下,目标虽然只减少到了三分之一,但在50和20的数值下,目标就减少到(50+20)/(50×20)=7/100。
换言之这就避免了我们沦落到步入垃圾遍地无法收拾的境地。
当然这种方法作为代价牺牲了自由度。因为是以相关性为前提的建模方式、"工人1可以用相同时间加工几乎所有的零件、工人2有擅长和不擅长的零件"类似这样的状况无法表现,所以这并不是万能的,需要我们灵机应变改变战术吧。
这种建模方式称之为"参数化",是在生产排程软件种常用的便利的方法。对于减少数据量、以及提高数据的再利用率很有效。
在此聊聊更深入的话题。
在本例中,数据以"二维立方体结构"的形式进行排列和分析,由两个"维度"组成,
即工序的能力值和资源的技能系数。 我们认为在运用中这几乎可以覆盖所有的应用范围,
但 FLEXSCHE DataTuner 最多可以支持四维立方体结构。
发布DataTuner!
我们认识到广大制造业对数据调整功能的需求已经很久了,但直到前年我们才开始具体构思和设计。 渐渐地,实现数据调谐器的机制变得清晰起来,经过反复实验,终于走到了这一步。
DataTuner如下使用。
- 花足够的时间积累基于大量的工作绩效的样本数据
- 从存储的数据中去除噪点并对其进行统计处理
- 构建和分析数据以推定应有的能力值
- 人为决定是否以推定值更新各个参数
DataTuner的分析过程,甚至估算的呈现都是自动的,但它不会自行更新主数据值。 对于每个推定值,都会提出一个 "建议度",并由用户决定是否采用每个推定值。在多维度的状况下很难立即判断是否应该应用推定值,这种情况下一定会更看重建议度协助判断吧。
顺便聊聊"打乱了计划"这个说法,当然不是计划自身乱了、而是"现实是变动的"(当然也由原有计划出错等情况)。由于问题和波动,生产现场 "一定 "会有变化,所以无论你的计划多么精确(或优化程度多么高),都只是一个 "计划",我们是无法 "预见 "变化万千的现实世界的。 计划和计划执行的目的不是 "按计划进行每项工作",而是在宏观整体上 "保持计划数量(→产量)和时间(→交货期)的情况下不断持续生产"。
因此一切最终都在于如何在以变动为前提的同时,"适应"这种变动并同时牢牢把握住数量和时间。 为此,能够正确估算(概率上合理的)产能是必须条件。 如果估计太高,工厂无论如何努力都无法履行其责任,如果估计太低,产能就会被白白浪费。 基于正确的能力值进行计划是非常重要的,FLEXSCHE DataTuner就是为了这些而诞生的。
承担"适应变动"的产品FLEXSCHE CarryOut。如果这两者在规划和执行的循环中一起配合使用,那么我们就能够做好迎接更多课题的挑战吧。

另外使用FLEXSCHE DataTuner积累的实际工作时间可以通过FLEXSCHE CarryOut进行采集,这真可谓一石二鸟。
下次博客中将向大家具体介绍最新产品FLEXSCHE DataTuner!
|返回员工博客页首|